前言
2022年5月13日,英伟达发布了Linux开源GPU内核模块,支持数据中心所用的GPU和消费级显卡,这意味着开发者可以通过代码而观察到内核驱动是如何工作的,同时还可以将 NVIDIA 驱动直接安装在企业内部的服务器上。
处于AI浪潮的大背景下,背后的推手不言而喻,长期以来 NVIDIA 一直以高性能 GPU 和闭源驱动程序而闻名。闭源一直是 Linux 社区和其他开源社区所厌恶的,这场由 Linus 与 NVIDIA 长达十年的冲突在开源内核模块后似乎画上了句号。
看似开源社区取得了胜利,但 CUDA 作为 GPU 的核心依然是闭源的。这个由 NVIDIA 推出的并行计算架构和编程模型,它允许开发者使用 C/C++ 直接在 NVIDIA 的 GPU 上进行通用计算,通过 CUDA 开发者可以更加高效利用 GPU 的并行计算能力,加速各种计算密集型任务……CUDA 的存在让 GPU 资源变成一种通用的计算资源。这是 NVIDIA 在软件领域上的核心,从目前的趋势和 CEO 的态度来看,几乎不存在开源 CUDA 的可能。
但无论如何,至少开源社区拿到了 GPU 内核模块的源码。
Kubernetes GPU 管理
从2016年起,Kubernetes 社区中希望能在集群中对 GPU 硬件加速设备进行管理的声音越来越大,对于云用户来说,他们想在 Pod 中能访问到 GPU 设备和驱动目录,以便进行大规模计算。
阿里的魔搭社区依靠着扎实的虚拟化技术和GPU资源,阔绰地赠送上百小时的计算时长,但依靠的是云主机,在面对大规模计算时可能因为无法抢到有限的计算资源而陷入停摆。
早在2021年,OpenAI 分享了一篇文章《Scaling Kubernetes to 7,500 nodes》其中记录了他们 Kubernetes 集群规模的成长与经验的分享,这说明在21年前 Kubernetes 社区就已经解决了 GPU 硬件的挂载和管理。
那么,如果想要在集群内实现 GPU 设备的管理,需要使用哪些技术?
Linux 中 Cgroups 暴露出来的操作接口是文件系统,它以文件和目录的方式出现在 /sys/fs/cgroup 路径下,可以通过挂载的方式自行挂载 Cgroups,在这个文件夹下会包含 cpuset cpu memory 这样的子目录,这些子目录代表着可以被 Cgroups 所限制的资源种类。
根据上述推理,如果想要在容器内使用 NVIDIA 的 GPU 设备,那么这个容器必须挂载 GPU 的设备和驱动目录。

Kubernetes 在实现 GPU 设备时,直接设置容器的 CRI (Container Runtime Interface) 参数就可以通过 Volume 将 GPU 驱动信息挂载到容器内,这也是 Linux 系统的特点,一切皆文件,只要设置好参数挂载驱动目录后就能直接使用该设备。
NVIDIA 开源了一个名为nvidia-container-toolkit的项目,包含了容器运行时库,用于自动配置容器使用 NVIDIA GPU ,这样可以不需要在启动容器时设置额外的参数。
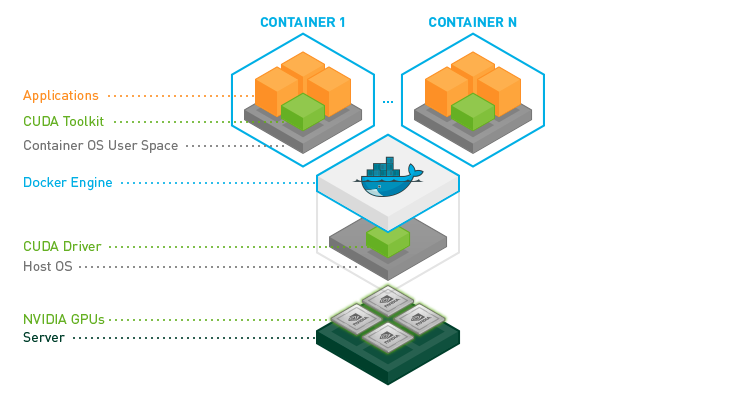
容器化只是第一步,如果要将 Kubernetes 与 Docker 一起使用需要将 Docker 配置为 NVIDIA Container Runtime 的引用,并设置为默认运行时。docker 的 daemon.json 文件内容如下:
1 | { |
在 Kubernetes 支持的 GPU 方案里所有对硬件加速设备进行管理的功能,都是通过 Device Plugin 插件来实现的。NVIDIA 会实现一个叫做 k8s-device-plugin 的插件,以官方的调度示例为例:
1 | $ cat <<EOF | kubectl apply -f - |
Device Plugin 会通过 Kubernetes 的 ListAndWatch API 定期向 kubelet 上报该 Node 上 GPU ID 信息,不会包含 GPU 设备的信息,这一点将插件和实际的显卡信息做了解耦,kubelet 通过双层缓存来维护这些 GPU 的 ID 列表,并通过 ListAndWatch API 定时更新。
当一个 Pod 想使用一个 GPU 时,开发者只需要在resources中添加nvidia.com/gpu: 1这样调度器会从缓存中查询符合条件的Node再对双重缓存里的 Gpu 数量减去相应的数量,完成 Pod 和 Node 的绑定。
现实的情况是复杂的,一个 Node 上可能包含多个 GPU 设备,这是由硬件资源来决定的,当 Pod 绑定某个 Node 后 kubelet 会根据设备ID 找到对应的设备路径和驱动目录,这些具体的 GPU 信息也是由 Device Plugin 维护。当 kubelet 将这些信息追加在创建容器所对应的 CRI 请求中,CRI 再发给 Docker ,创建出来的容器中自然就会出现这个 GPU 设备。
这是 Kubernetes 为 Pod 分配 GPU 资源最简单的实现方式,它只能按照 GPU 的个数进行分配,在 Device Plugin 的设计和实现中很难对 ListAndWatch API 做更多的扩展,这源于它本身的扩展性就不好,如果面对一些更复杂的场景需求,是无法通过 Device Plugin 的 API 来实现的。
GPU Share
随着机器学习对 GPU 资源需求的日益增加,单卡资源的分配已经无法满足机器学习的需求,模型训练的过程中衍生出多种复杂场景:小任务场景下希望能在一张卡上执行多个任务以提高利用率,大任务场景下希望一次训练能调用多张卡进行并行计算。
如果需要在一张卡上运行多个推理任务,需要解决的问题是:如何在 Pod 之间共享 GPU?
阿里推出一个开源的 GPUShare调度器扩展它基于调度器的扩展和设备插件机制,在 Kubernetes 中实现将一卡分配给多个 Pod,随之而来创建资源也发生了变化:
1 | apiVersion: apps/v1 |
资源的划分不再以卡为单位,而是采用内存G为单位,当使用插件查看共享的 GPU 资源信息时能轻易发现当前集群的 GPU Memory 占比:
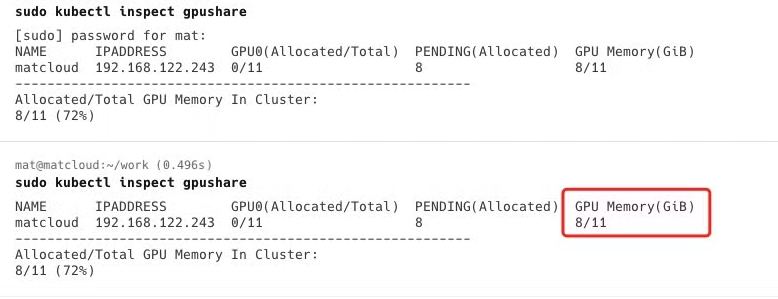
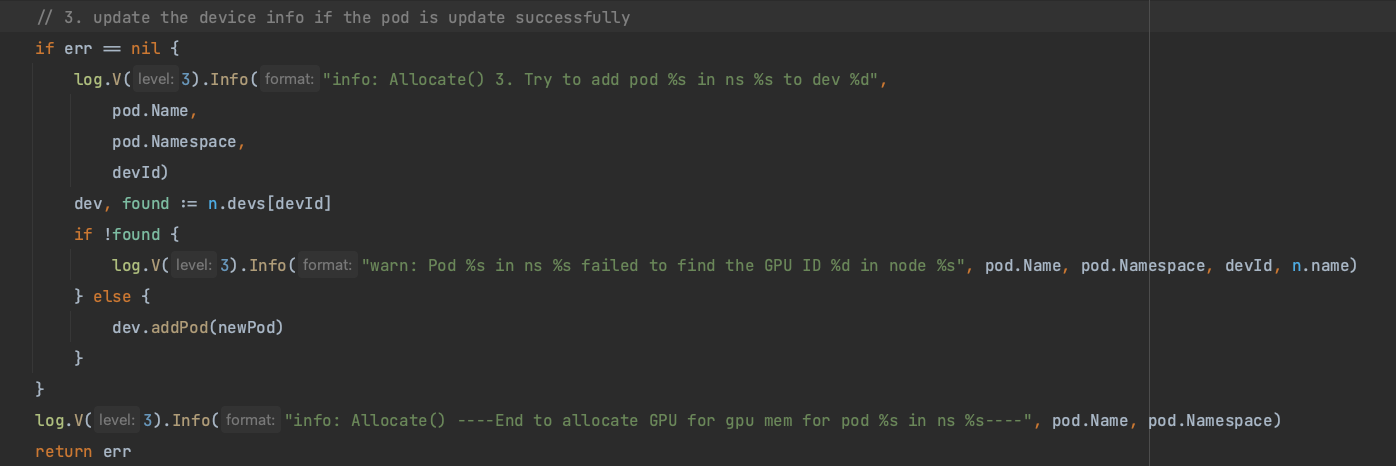
在该项目的 README 能发现共享的解决方案基于Nvidia Docker2(这个项目现在已经封存了),通过参考 GPU 共享设计完成该项目,虽然gpushare-device-plugin已经停止维护,但从源码的设计来看可以发现,它的实现方式和 **k8s-device-plugin**的思路相似,整个过程大致分为三步:
1.查询所有的GPU ID 设备,如果查询到了,那么更改 Pod 的 Spec 信息
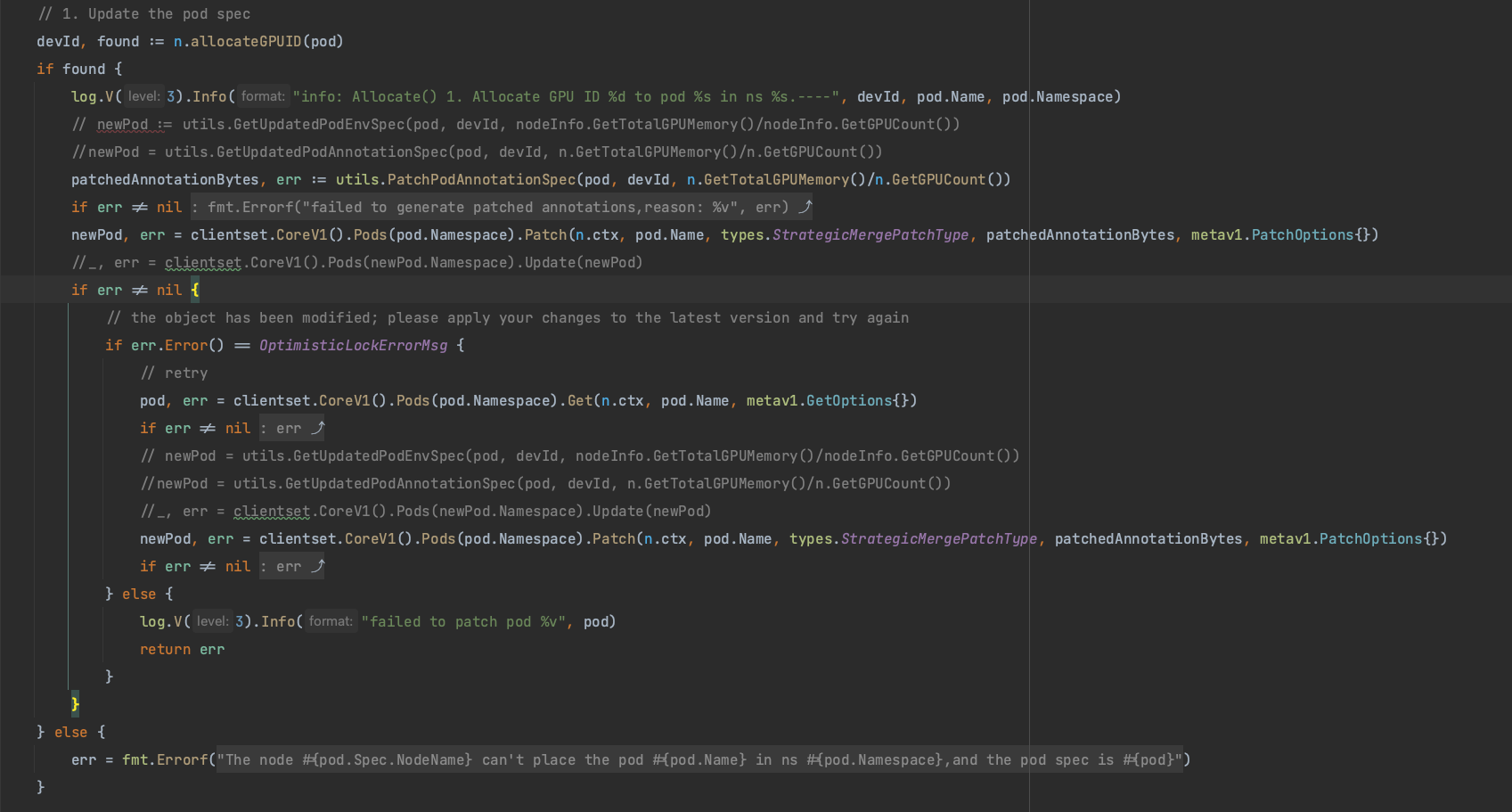
2.将Pod 绑定到指定的 Node 上
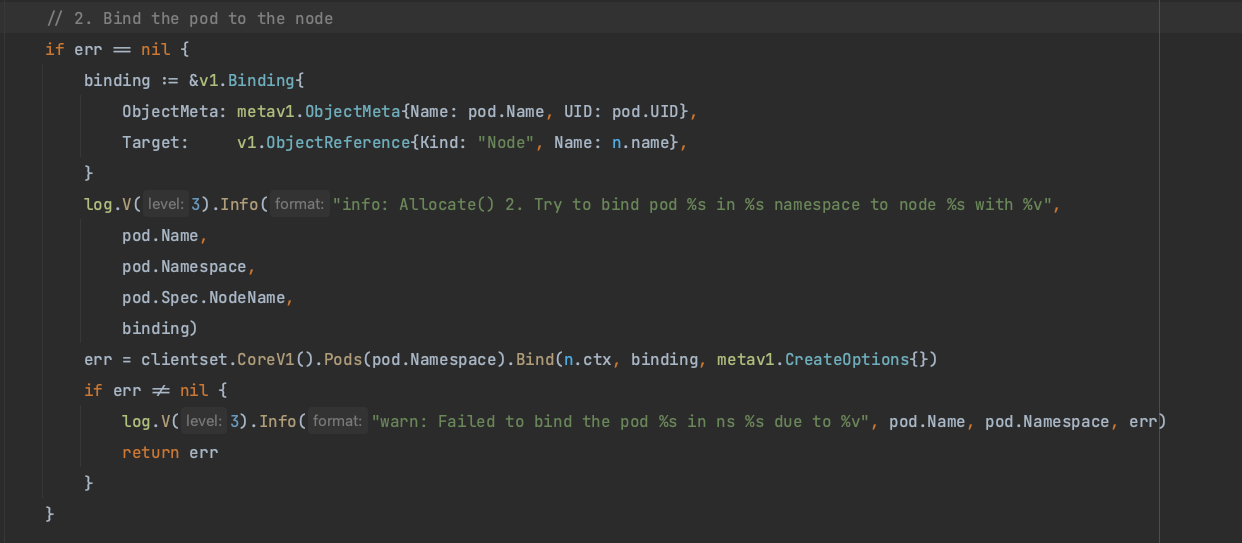
3.如果pod更新成功,更新设备信息
将一个设备信息同时挂载多个 Pod 是实现小任务共享的简单方式,GPU Share 通过插件和调度器动态遍历所有 Pod 的显存信息来计算所能调度的 GPU 资源,以扩展的方式来进行资源分配。这种方式实现成本低,但也会存在问题:GPU 资源不隔离。
当 Pod 中的计算任务在申请显存时,因为资源的不隔离,所以它实际上能申请超过分配给它的显存数。假设有一张 80G 的显卡,按照正常流程可以分配 4 个 20G 显存的 Pod,当其中的某个 Pod 申请显存时多申请了 5G ,这样会引发资源的抢占从而导致其他 Pod 在申请 GPU 资源时出现显存溢出的错误。
异构算力虚拟化中间件
HAMI 是一个异构算力虚拟化中间件,它包含多任务共享一张显卡并可限制分配显存大小,比如可以用显存值(M)或显存比例(百分比)来分配GPU,vGPU 调度器确保任务使用的显存不会超过分配数值。
1 | resources: |
使用场景:
- 云原生场景下需要复用算力设备的场合
- 需要定制异构算力申请的场合,如申请特定显存大小的虚拟GPU,每个虚拟GPU使用特定比例的算力。
- 在多个异构算力节点组成的集群中,任务需要根据自身的显卡需求分配到合适的节点执行。
- 显存、计算单元利用率低的情况,如在一张GPU卡上运行10个tf-serving。
- 需要大量小显卡的情况,如教学场景把一张GPU提供给多个学生使用、云平台提供小GPU实例。
它包含显存资源的硬隔离:
HAMI 包含一个统一的mutatingwebhook,一个统一的调度器,以及针对各种不同的异构算力设备对应的设备插件和容器内的控制组件。
从它的开发计划表来看,NVIDIA 的 GPU 支持显存隔离,算力隔离,多卡推理。截止到2024年9月13日为止还不能支持华为的卡,从实践上在通过 Helm 安装 HAMI 时会遇到服务器不支持华为的错误,需要删除 Helm Chart 关于相关的资源信息。
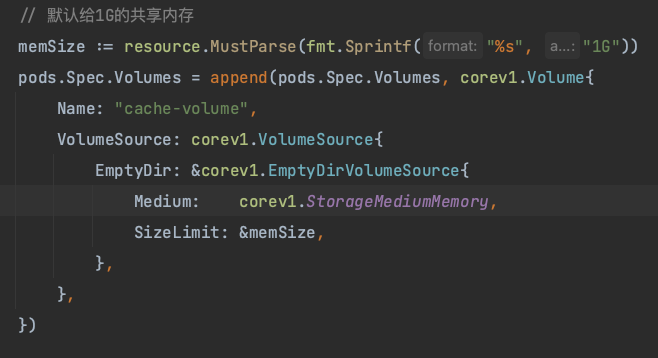
因为支持多卡推理,在现实中在申请内存分配时,可能会遇到访问共享内存错误。Linux 中包含一个共享内存的概念(Shared Memory) 它是一个临时文件系统,可以让用户操作磁盘中的文件一样来读写内存。在多卡推理时会让多个进程高效地存取一些临时文件,实现”进程内快速共享内存”。Linux 系统中/dev/shm 的大小一般为物理内存的一半,但是在 Docker 启动容器时会给 /dev/shm设置一个默认的大小,即 64M。
Docker 可以通过 --shm-size=1g指定一个容器的 shm 大小,在 Kubernetes 中则可以通过 emptyDir 的方式配置:
HAMI GPU 资源的强隔离性不能解决所有问题,比较现实的是随之而来的显存碎片化问题,当单卡多任务和多卡多任务的混合场景时,就会出现资源不均衡,碎片化的小任务抢占了多卡支持的大任务,导致 Pending 的情况。
这种情况可以编写相应的调度策略,无论是按照任务排列的优先级,还是抢占调度的方案都能尽量避免碎片调度的问题。
总结
本篇介绍了 Kubernetes 在管理 GPU 设备时的具体实现思路,从 Docker 实现 GPU 驱动和设备的挂载,到 Kubernetes 的开源项目来解决大规模的机器学习。可以看到在人工智能领域上,对 Kubernetes 集群的使用要求比以往更高,无论是从 OpenAI 从 2500个节点扩展到 7500 个节点,每个节点仅调度一个 Pod 独占全部资源来达到算力最大利用化,还是在一张卡上执行多个较小的计算任务,这些都离不开 Kubernetes 社区和 CNCF 在人工智能领域的大力支持。
值得关注的点是阿里虽然开源的项目不再维护,但阿里云的 ACK 已经支持各种异构计算资源进行统一调度和运维管理;HAMI 虽然目前不支持华为的卡,但计划任务中也在积极适配(即使它无法做到多卡支持);华为的 Volcano 和 NPU 插件能实现在 x86、Arm、GPU、昇腾、昆仑等多元算力的统一调度;