前言
存储一直是系统中最重要的部分,在云计算推动的当下,一方面平台需要用户创造的数字资产作为信息壁垒,另一方面平台也有责任和义务保全用户托管的信息。随着平台的用户数激增,对存储系统的要求也越来越高。
一个高扩展,高性能,高可用的分布式存储系统是系统稳定的重要基石,存储系统中大致可分为三部分:块存储,对象存储,文件存储。在主流的分布式存储中 HDFS 可以作为文件存储的代表;Swift 作为对象存储的代表;Ceph 同时提供了块,文件,对象三种存储方式,于是被称为统一存储。
Ceph
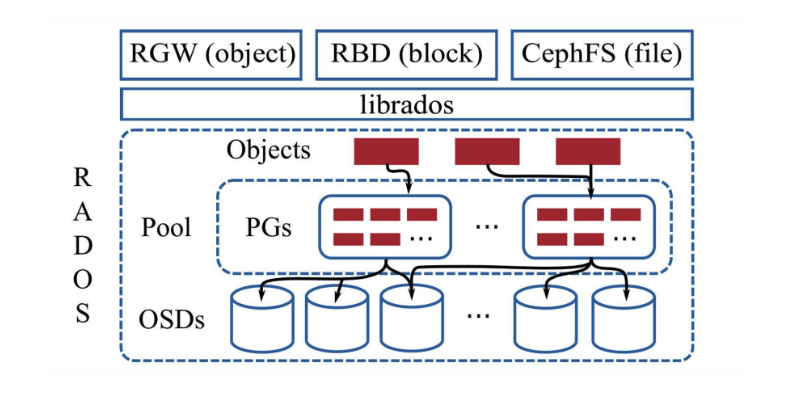
分布式文件系统能对多个物理机上的存储空间进行管理,并对外提供并行I/O,存储容错,动态的水平扩展以及强一致性。Ceph 是当前最流行的开源分布式存储系统,它的核心是可靠自主的分布式对象存储(Reliable Autonomic Distributed Object Store , RADOS) 通过该模块可以水平扩展大规模 OSDs 提供自愈,自管理并强一致性的副本对象存储服务。
RADOS 中的对象会被存储在逻辑分区(Pool); 对象会在池中分片,每个分片单位被称为放置组(Placement Groups PGs) 放置组中的数据会根据配置好的副本数同步到多个 OSD上,这样可以在单个 OSD 宕机时保证数据的正确性。
RADOS 集群中的每个节点都会为每个本地存储设备运行独立的 OSD 守护进程,,这些进程会处理来自 librados 的请求并配合其他的 OSD 节点完成数据的拷贝,迁移以及错误恢复等操作,所有的数据都会通过内部的 ObjectStore 接口持久化到本地。
下图来源于分布式存储 Ceph 的演进经验 · SOSP ‘19
传统的分布式文件系统一般都会直接将本地的文件系统直接作为存储后端,以本地文件系统作为基础构建更加通用的文件系统,但以 Zed 编辑器为例,在无法满足更加复杂的场景下,才会选择从最底层重新构建,以适配更加灵活和复杂的场景需求。如今的Ceph存储后端没有直接使用本地文件系统,而是直接管理本地的裸设备。这么做的原因有三点:
1.直接在本地文件系统上构建无额外开销的事务机制是非常复杂的
2.本地文件系统的元数据性能对分布式文件系统的性能有很严重的影响
3.成熟的文件系统有非常严格的接口,适配新的存储硬件很困难
事务实现
事务通过一系列操作封装成一个原子单元来简化开发工程师的工作,但作为一个文件系统支持事务是非常有难度的事情。在 SOSP ‘19 论文中提及三种实现事务的方式:
1.基于文件系统内部的事务
部分文件系统为了实现原子性地执行一些复合操作,选择在内部实现事务,要注意的是这些机制仅仅用于内部,开发工程师对原有文件系统如果不太理解,可能无法利用其内部事务,同时因为仅为内部使用,在拓展性上会非常受限。
2.用户空间实现逻辑预写式日志(Write-Ahead Log、WAL)
当事务执行时,首选会对所有的事务提交进行一个序列化,然后写入日志,在提交事务,再提交到文件系统。这里的每个事务在执行前都需要读取前一个事务的执行结果,以作为回滚的依据,很明显这种多种严重的方式会导致事务提交非常低效。
使用这种方式也需要承担一定的风险:错误恢复重放日志时数据会发生错误,严重的情况下会导致数据损坏
3.使用支持事务的键值数据库
这种思路类似于引入中间件分布式锁,将元数据存储在RocksDB中,但对象依然使用文件系统存储,在存储中写入对象时要分别写入文件和RocksDB,并且需要调用两次fsync函数,这样会带来额外的开销。
元数据操作
元数据是文件系统中重要的组成部分,元数据操作直接影响着文件系统的性能和表现。元数据操作本质上是一种事务操作,文件系统中的元数据操作通常情况下是由一系列的基本操作构成,在事务操作时,工程师们希望它总能保持一致性:要么全都完成,要么全都失败。
如果一个元数据操作没有全部完成时发生故障,就会产生一部分的数据写入磁盘,另一部分的数据由于还没写入而丢失。当服务重新恢复后会发现数据的不一致性,这点是无法容忍的,比较常见的方法是使用日志技术来作为恢复的依据。
另一种情况是事务的并非执行,当多个元数据并发操作时,如果不进行加锁,可能导致多个元数据子操作相互覆盖,从而产生意想不到的错误。
硬件设备扩展
成熟的本地文件系通常在设计时就限定了接口的扩展性,随着存储硬件的发展也带来更多的工作量,对分布式文件系统也带来了更多的挑战。当我们回顾Ceph的演变历史会发现,最初的存储引擎实现为 EBOFS(Extent and B-Tree-based Object File System),本质上也是在文件系统上做了扩展。
在2011年正式使用XFS作为Ceph存储后端之前,Ceph团队还尝试过使用其他文件系统如ext4、ZFS等作为存储后端,但最后选择了XFS,因为其具有更好的伸缩性,元数据的操作性能也较好。
从NFS 到 Rook Ceph
Network File System NFS 网络文件系统,它的主要功能是通过网络让不同的机器,不同的操作系统能够彼此分享数据,应用程序也能通过网络访问位于服务器磁盘中的数据。
它的基本原则是:允许不同的客户端和服务端通过一组RPC分享相同的文件系统。
在云原生的环境下,NFS也可以被当作整个集群的共享目录:
1 | 集群中的每个节点都需要安装 |
Rook 是一个开源云原生存储编排器,为 Ceph 存储提供平台、框架和支持,以便与云原生环境原生集成。
Rook 自动部署和管理 Ceph,以提供自我管理、自我扩展和自我修复的存储服务。它可以通过在 Kubernetes 资源上构建来部署、配置、预置、扩展、升级和监控 Ceph 来实现这一点。
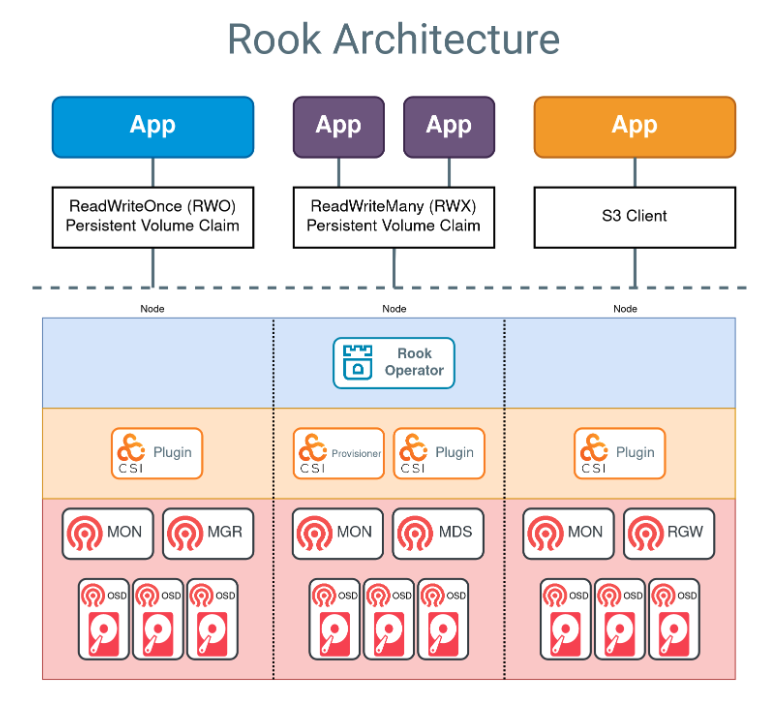
Rook 允许通过自定义资源(CRD)创建和自定义存储集群:
- Host Storage Cluster:使用主机路径和原始设备的存储
- PVC 存储集群:通过指定 Rook 应该用于消耗存储的存储类(通过 PVC),在 Rook 下动态配置存储
- 延伸存储集群:将 Ceph mons 分布在三个区域中,而存储 (OSD) 仅在两个区域中配置
- 外部 Ceph 集群:将您的 K8s 应用程序连接到外部 Ceph 集群
NFS的优点在于跨节点文件共享,可以直接利用现有的存储目录文件,对基础设备要求低,降低了成本。但受限于性能,NFS通常情况下要比本地存储慢,当集群规模扩展时,NFS服务器作为单点目录如果发生故障,影响面甚广,也不易于迁移和扩展。
Ceph 经过十几年的技术发展,是流行的开源分布式存储服务之一,作为分布式文件存储服务它在过去十几年里经受了时间的考验,在如今云原生时间背景下,它提供的高性能,可靠性,一致性也成为云服务的基石。
后记
本篇文章简单介绍开源的分布式框架Ceph,同时简要对比了一下云原生存储的方案。从作者本人的角度来看,我们在设计基础设施框架时也能从Ceph的技术选型和演变中借鉴到经验和教训:
在集群规模不时,可以使用NFS快速搭建,以低成本的方式快速试错,当系统发展到一定规模时就要考虑存储的安全/稳定/扩展性。