前言
当一个新事物的出现,最好的办法就是了解它出现的背景,发展的历史。
当ChatGPT出现在我们面前,多轮对话能力让人震惊,仿佛机器真的可以”理解”人类语言。不同于当时Siri一样的语音助手,ChatGPT的准确率相比之下非常高。
于是一夜之间AI的浪潮袭来,时至今日各个厂商相继公开自己的大模型并不断迭代:GPT-4-Turbo,Qwen-Max,智谱清言GLM-4等。AI能力也从最初的对话型衍生出多种:图片生成,语音识别,文档解析,代码补全,视频生成,AI搜索……
当技术发生了翻天覆地的变化和革新,不管是否愿意,时代的浪潮会推着我们前进。同时技术变化也不是徐徐图之,而是剧烈革新代替。我们回头看,云原生技术的推进是如此,移动互联网时代也是如此。所以我们应该积极了解AI到底是什么,从而明白AI能做哪些,不能做哪些?它又能给我们带来哪些技术上的革命。
ChatGPT
如果说从名称上看Chat代表着’聊天/对话’,那么GPT又代表着什么呢?
GPT全称为 Generative(生成式) Pre-trained(预训练) Transformer(转换器),从这三个词透露出来的信息,如果不负责的猜测一下是不是意味着:”将人类语言转换为机器能识别的信息,经过反复训练就能得到生成式的AI模型?”
事实上Transformer是一个神经网络架构,它在神经网络架构中引入了注意力这一概念。在现实生活中一些场景上下文是有关联的,比如一小段视频是由多张图片连续组成,对话也有上下文作关联。将这些存在一定关联的数据做特殊处理以后,它们被称为“时序数据”或序列(sequence),Transformer 在实际任务中就是将一个序列转换为另外一个序列。将一段中文转换为一段英文,将一个问题转换成一个回答……这就是Transformer名称的由来。
Pre-trained,预训练代表着模型的训练方式,在神经网络训练中采用更大,更多的参数先对模型进行训练,然后再进行微调。通俗一点讲就是九年义务教育,让模型拥有一些基础的通用能力,微调则代表着某一方面的偏重技能,就像选专业一样。
ChatGPT采用基于人类反馈的强化学习(Reinforcement learning from human feedback, RLHF)来进行预训练微调。整个过程分为三步:
1.预训练一个语言模型:从优质的数据集中拿出一部分的数据,然后监督模型的训练
2.收集对比数据并训练奖励模型:输入数据和模型输出被采样,通过输出结果人工反馈输出的质量,给予模型回应或评分。
3.从第二步的数据采样中得到新的数据,使用强化学习的方式微调语言模型。
RLHF是用于训练AI的特定技术,它可以让模型更加精准,人工的干预也可以让模型显得更有”人性”。同时数据集的量级也是一个重要因素,OpenAI 在训练GPT-1模型参数只有1.17亿,到了GPT-2就提高了15亿,GPT-3更是增长到了1750亿,这已经是呈倍数增长了,而到了GPT-4模型宣称有1.8万亿。
可能单纯提及数字并不能真正体现出这个量级的数据集意味着什么,对于有过写作经验的工程师来说能体会的更深一点。有一些教你如何写作的书中总会强调,多看一些别人的文章,多写点文章,这样写作能力自然就提高了。想象一下,你需要看多少本书才能写一本书?假设输出一篇两千字的博客,那么一本二十万字的书则等价于上百篇的博客。
质量问题本质是数量问题,当数量级成倍增长,那么大模型的能力也由量变转为了质变。
在简单理解了Transformer和Pre-trained之后,应该怎么理解Generative呢?
生成式代表着AI可以创造新内容和想法,在学习基础语言后它能创造新地根据某一要求进行创作,例如可以让AI学习中文,根据词来写一首诗。经过预训练后ChatGPT会学习字,词,语法规则,上下文信息来预测下一个单词或短句,这个行为会涉及到数据分析和统计学。
在GPT底层下,深度学习模型不断重新创造它们从大量训练数据中学会的模式,然后在设定的范围参数中工作,根据学到的知识在创造新的内容。
深度学习模型通常不会存储训练数据的副本,而是会将数据进行编码,使类似的数据点被安排在彼此附近。之后,再对这种表示进行解码,以构建具有类似特征的新原始数据。
Prompt Engineering
如果仅仅只是从ChatGPT这个名字上推断它代表的意义和底层技术并不精确,AI包含了计算机科学,数据分析和统计,语言学,神经学等多个学科。Transformer和Pre-trained无法解释ChatGPT多轮对话时展现出短期记忆能力,但在实际体验中多轮对话效果相当不错。

ChatGPT使用Prompt Engineering提示工程技术来提高多轮对话的效果,对于大语言模型来说,因为计算效率和内存限制,一般会设计固定的上下文窗口,限制输入token的数量。文本首先会被分词器(tokenizer)分词,并通过查表编号,然后embedding到矩阵中变成高维空间向量,这是文本向量化的过程。
下图仅仅只是一个流程化展示,并不严谨:
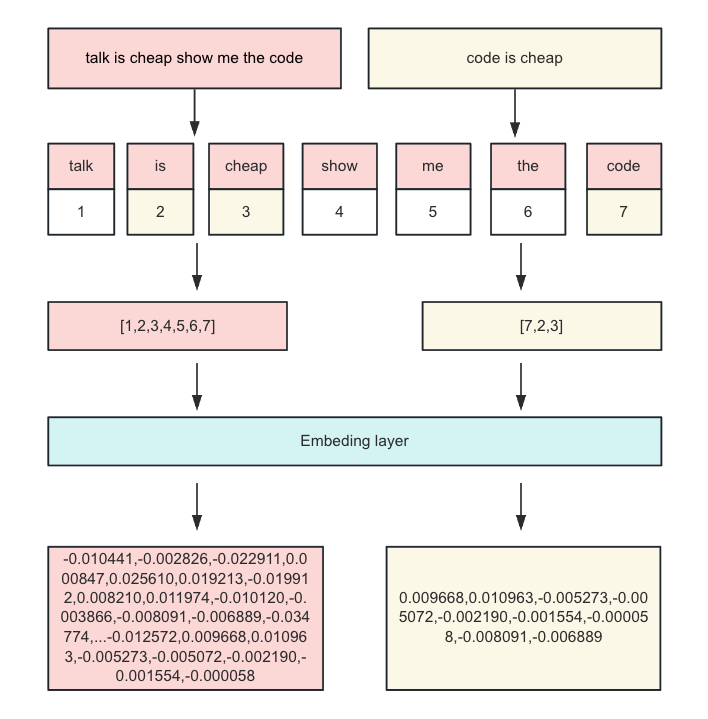
由于token的限制,需要在有限的输入窗口将信息描述的更加全面,以提高大模型的准确度,这就需要使用Prompt Engineering工程来优化。提示工程在与语言模型交互,对接,理解大语言模型能力等方面都起着比较重要的作用。零样本提示与少样本提示在复杂任务上截然不同,如果把大模型比做一个懵懂的孩童,提示词工程便是循循善诱的教案。
神经网络
人工智能领域一直存在两大流派,”符号主义”(逻辑推理)和”联结主义”(仿生学),神经网络是模拟人类大脑理解而设计的模型,基于神经网络构建的大模型也可以像大脑那样工作并理解。在上文中提到ChatGPT使用Transformer作为它的基础架构,而Transformer又是一个引入注意力机制的神经网络架构,那么什么是神经网络?
1957年,康奈尔大学心理学教授罗森布拉特实现了一个神经网络模型,他称之”感知机”(Perceptron)。他将一组神经元组合在一起,训练机器视觉模型识别方面的任务。
神经元是神经网络中最小信息处理单元,在生物学中神经元具有感受刺激、整合信息和传导冲动的能力。神经元感知环境的变化后,再将信息传递给其他的神经元,并指令集体做出反应。
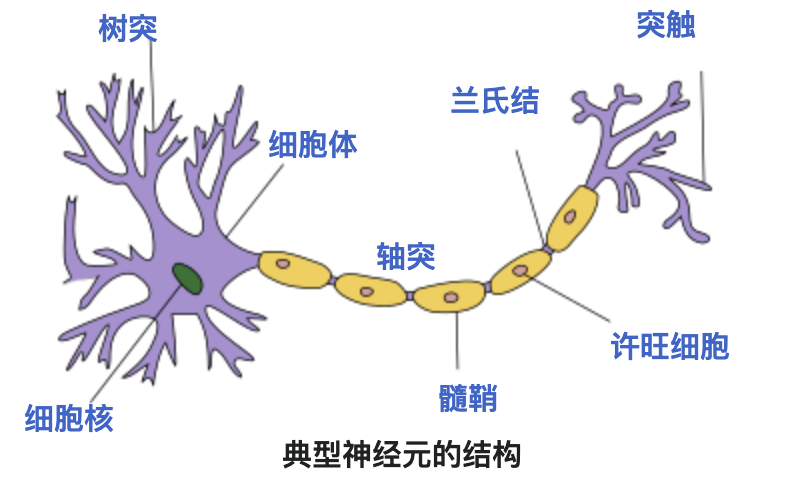
计算机科学家模拟生物神经元的特性,抽象出一个简易的模型:
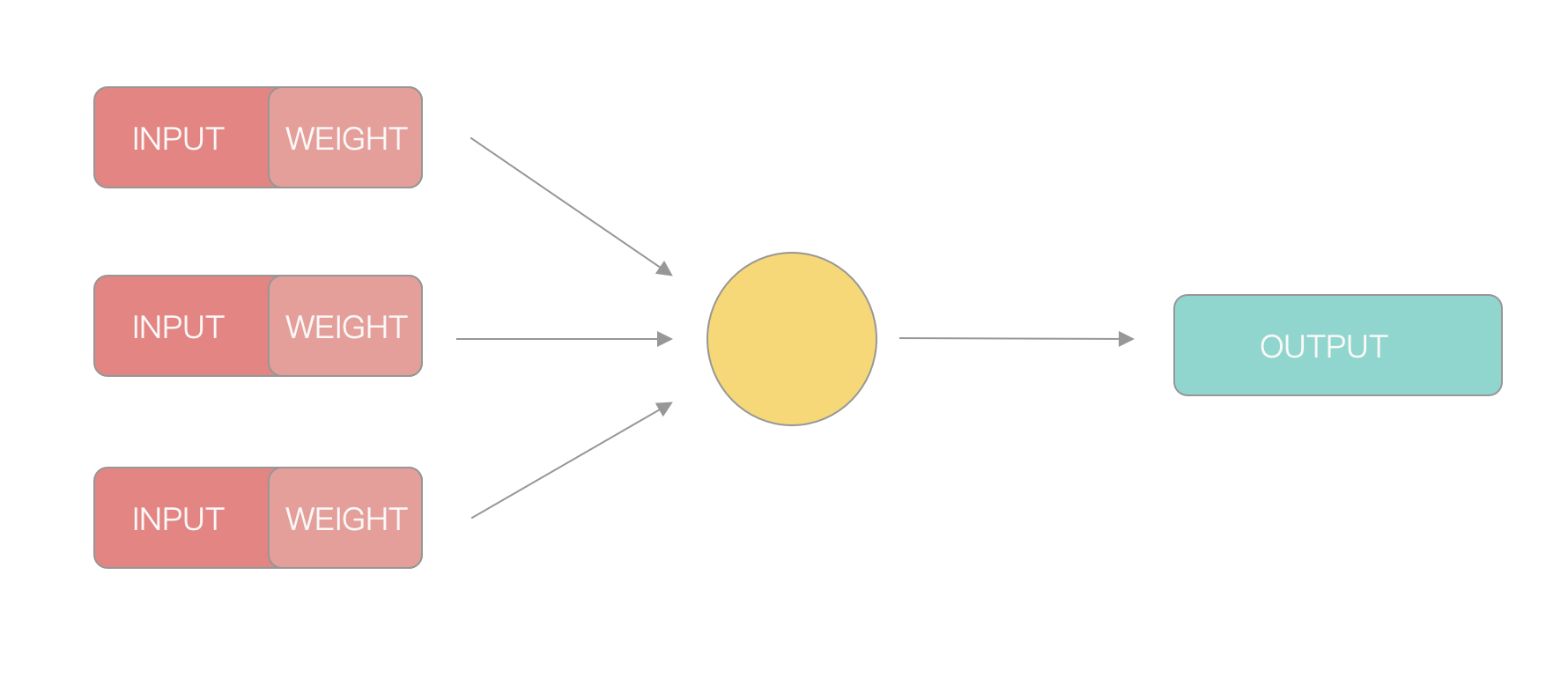
在这个模型中,一个神经元会接受多个来自其他神经元传递过来的输入信号,不同的输入信号的权重也不相同,神经元将所有输入的值按照权重加圈求和,再将这个结果跟神经元中的”阈值”进行比较,如果等于或大于这个阈值就对外输出信号,反之异然。
在现实世界中判断一件事是否可行,往往是由多个因素决定,不同因素的权重也不相同。例如打算明天出门骑行,这时会考虑多个因素:
1.自行车是否正常 10
2.明天天气如何 8
3.骑行路线是否通畅 2
4.是否存在同伴陪同 3
不同因素的重要性也不同,自行车坏了基本上宣告计划破产,而天气也会变成决定性因素,但骑行路线和同伴是否陪伴相比之下只是算次要因素。将这些权重全部加一起再和阈值作为比较,阈值的高低代表了意愿的强烈,阈值越低代表这件事越容易通过。
下图来源于《从神经网络到 Hugging Face》
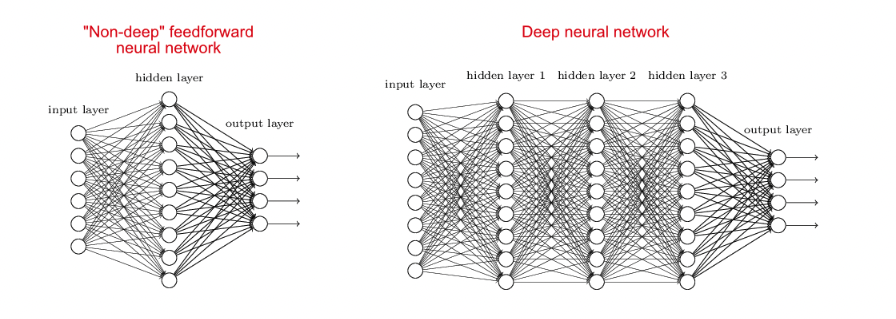
单个的感知器构成一个简单的决策模型,但是在现实世界中是不够用的。神经网络分为浅层神经网络和深度神经网络,当然这都是相对而言。上图左边的浅层神经网络一般只会有一个中间层,加上输入/输出层,也仅仅只有三层。深度神经网络的中间层不只一层,ChatGPT就是由一种或多种深度神经网络构建而成的。可以将深度神经网络看作多层多个神经元的组合。
构建一个深度神经网络大量的参数,修改一个参数将会影响其他参数行为,深度学习训练中使用损失函数(loss function)来衡量这些指标,通过损失值来衡量神经网络模型在训练样本效果的好坏。
最开始科学家对神经网络的参数随机赋值,输入一批训练数据,得到预测输出后计算损失函数。然后再用输出的数据反向计算,根据这个过程来矫正参数让损失值变小。经过反复训练,让模型不断学习进步,最终得到我们所看到的大模型。实际上的深度学习要比作者描述的要复杂得多。
在深度神经网络中,这些数值可以分为两类,一类是层数、激活函数、优化器等,称为超参数(hyperparameter),它由工程师设定;另一类是权重和偏置,称为参数(parameter),它是在深度神经网络训练过程中自动得到的,寻找到合适的参数就是深度学习的目的。
从现阶段市面上的大模型我们也能看出,模型的性能与模型大小,数量以及计算资源相呼应。模型越大,数据量越大,分配的计算资源最大,模型的性能越好。深度学习人工智能技术正在以爆发式发展,预训练+微调的方式促进了神经网络训练资源的共享,从上文来看深度学习所需要的算力才是关键,谁掌握更多的算力谁训练出来的模型也就相对优质,这既是门槛也是瓶颈。
后记
以ChatGPT为例窥探AI的冰山一角,现在回到最初的问题,AI能帮助我们做什么?
从市面已有的AI应用来看,AI能辅助检索(AI搜索引擎),能分析处理数据并加以预测(但并不准确)。AI因为黑盒的深度学习对执行认知有着天然限制,同样的提示词,同样的问题可能第一次回答准确,第二次则无法得出期望的结果,这是大模型所产生的”幻觉”。从现在的一些AI应用来看,开发者使用提示词技术与Embeddings让大模型识别率更高,似乎想让模型提供更精准的答案。
也有科学家认为不应该消除”幻觉”,生物记忆本身就存在不完美性,幻觉这种特征代表了模型的创造力。这可能是在提醒开发者,如果完全消除”幻觉”,那和Siri又有什么区别呢?也许通过外部记忆的方式解决”幻觉”在某些特定场景下来带的问题才是最终解决方案之一?
从开发者的视角来看,Github Copilot等Ai产品确实能提高生产效率,无论是提供简单的函数提示,还是相对准确易懂的变量名,都大大节约了编码时间。但是在复杂函数编写的情况下,可能因为上下文信息过少,亦或者无法检索整个项目,提示出来的代码不够准确。尤其在并发编程下即使有注释的提示,生成出代码总是不尽人意。
让人惊喜的是,个人学习Rust时,AI提示生成的代码质量相当高(比初学者高),这可能因为语言门槛较高,而AI补充能很好降低编写门槛。
在排查问题时,AI给出的答案过于笼统,上下文的限制让AI无法精确定位问题所在,提供的解决方案也可能存在错误(这里涉及到知识库的滞后性以及幻觉问题)。也看到过一些AI结合低代码平台的产品,从目前效果来看可能短时间无法真正取代程序员。
在了解了AI技术对于工程师带来的一些变化后,我们来谈一下AI不能做什么。
AI虽然在经过RLHF的训练后生成出来的内容更加”人性化”,但无法真正理解情感或具有创造性思维能力。同时机器学习也缺乏道德和伦理的意识,没有办法进行道德判断或伦理决策。关于AI的安全方面也存在存疑,由于训练需要大量优质样本,可能包含了一部分敏感信息,关于版权与滞后的监管与审查,无法推断AI会存在怎样的风险。这可能会面临被黑客恶意攻击。
作者本人近两年一直在做云原生的基础设施建设,AI技术的发展增加了算力的需求,增加了大规模运用的场景,虽然云原生技术为AI应用提供了一定的基础,但是将AI的工作负载与云原生平台整合时,依然存在一些挑战。
AI技术的创新对于基础设施,例如网络,存储,监控等工具提出了更高的要求。在未来可能更多的推出基于AI与云计算结合的一系列应用或工具,让AI开发者轻松复用最新的人工智能成果,从而推动AGI的发展。
学习资源
https://hutusi.com/articles/the-history-of-neural-networks
https://www.ruanyifeng.com/blog/2017/07/neural-network.html
https://aws.amazon.com/tw/what-is/reinforcement-learning-from-human-feedback
https://developer.baidu.com/article/detail.html?id=1670936
http://neuralnetworksanddeeplearning.com/index.html