Go语言指针定义
Go语言中保留了指针这个特性, 虽然不能像C/C++那样进行指针运算, 但是它允许控制特定集合的数据结构, 分配的数量以及内存访问模式。
这个定义会让从未接触过指针的初级程序员难以理解, 不过我们可以依靠指针的使用方式来反推它的概念。
C# 中保留了对指针的操作, 但开发人员一般不会考虑去使用它,使用指针操作需要开启 “不安全的代码”选项
在Go语言中, 指针的使用涉及到两个操作符:& 和 *
我们通过下面一小段示例代码,来理解第一个操作符 &(地址取值)

我们发现, 加上&操作符后输出的值为0xc0000441f0这种十六进制的数据, 这是变量在内存中存放的地址. 但是这种十六进制的数据是机器识别的, 工程师们没办法直接对它进行更改.
这时候我们就需要使用第二个操作符 * 去接收内存取值的数据.
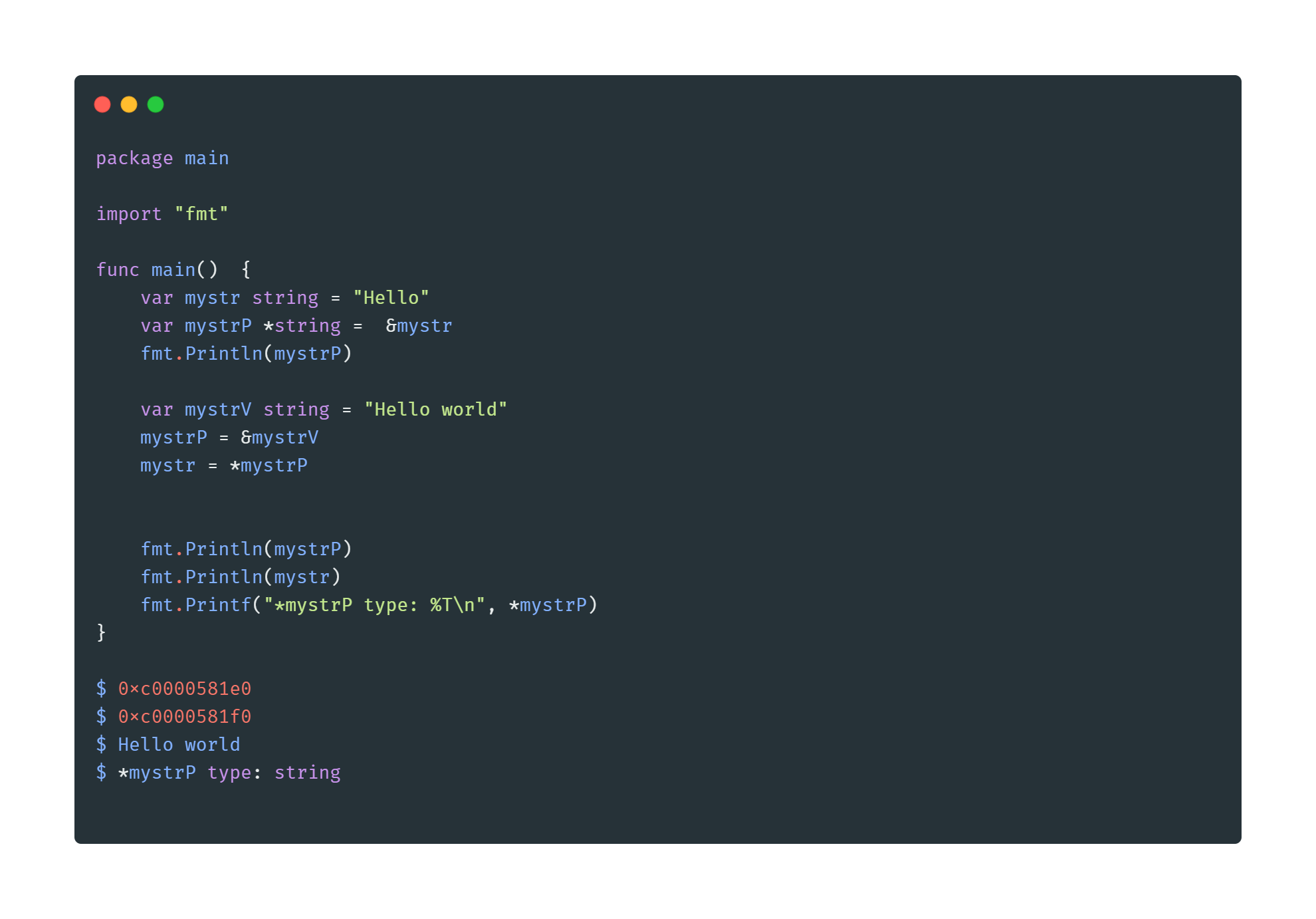
从上述这段代码我们不难看出, * 和 & 操作符的使用是互补的 & 取出来的值需要依靠 * 来接收, * 得通过十六进制数据来指向某一个变量的值.
仅仅指向内存地址是不能满足Go语言加入指针的初衷, 所以通过指针不止能够取值, 还能够修改值. 我们继续看上述代码, 在这段代码中我们为 mystrP 的赋了两次值, 一次是变量 mystr 的内存地址0xc0000581e0 ,此时它指向的内存地址已经发生了改变, 它现在指向的是 “Hello world” 的内存地址 0xc0000581f0
这里我们要注意一个地方: *mystrP 不是取 mystrP 指针的值, 而是 “mystrP 指向的变量”
通俗点讲, *mystrP 会根据0xc0000581f0这个地址找到 “Hello world” 我们根据打印 *mystrP 的类型也能发现, 它不是 *string, 它是一个 string 类型
这也能解释,为什么将 *mystrP 赋值给 mystr后, 打印的值不再是 “Hello” 而是 “Hello world ”
指针在函数中的使用
我们在声明有参函数时, 需要先考虑一个问题:是使用值类型, 还是使用引用类型?这个问题影响的是当我们在函数中对入参进行修改时会发生怎样的变化。
我们先揭露一个概念:Go 语言选择了传值的方式,无论是传递基本类型,结构体还是指针,都会对传递的参数进行拷贝。
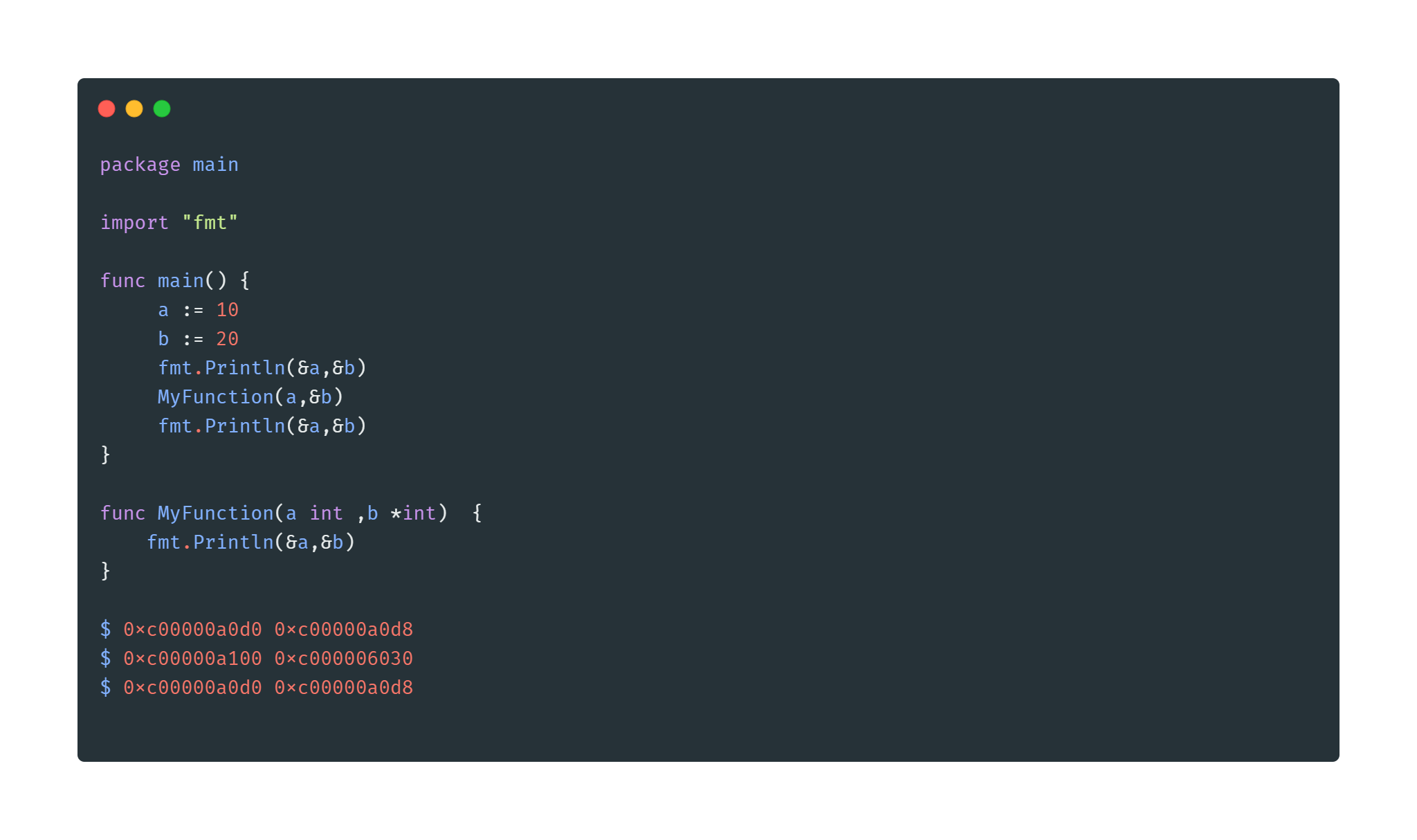
从运行的结果我们可以对函数传递变量的过程进行部分推断. 我们先看1, 2 组内存地址的变化, 它们都不相同. 这侧面印证函数在获取入参时, 没有直接使用原参. 而是在将参数传入函数时, 给传入的参数在内存区分配一个新的地址, 无论它是值类型还是指针类型。
接下来我们对比1,3 组, 在调用MyFunction 函数后内存地址没有发生变化, 这说明函数调用不会影响到原有参数的内存地址。
注意, 这里说的是不会影响到内存地址, 而不是原本的值。我们简单地修改一下上述代码,再来分析其中的原因。

在这段代码中, 我们在MyFunction函数中加入了一个修改值的操作, 并且将各个变量值打印出来进行对比。
先看 a 的变化,我们可以发现 a 在函数中进行过一次赋值操作, 从函数内打印参数也能发现值的确也发生了变化, 但是从打印的结果看来, MyFunction 函数中对变量 a 进行赋值操作似乎改变不了函数 main 的值. 这进一步验证 函数会对传递的参数进行拷贝 这个概念. 因为是值拷贝, 相当于在函数内部声明了一个局部变量 a 所以在函数内部修改无法影响到 main 函数中的参数.
看到这里大家可能会产生新的疑问, 既然函数对入参会进行拷贝, 那参数 b 在函数MyFunction内部进行参数的更改后为什么会影响到 main函数中的参数 b . 这里要注意的是:b参数是使用指针进行传递的, 在函数内拷贝的指针会指向原有的内存地址.
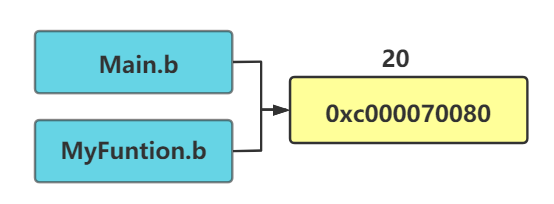
这种模式可以理解成两方访问的公共变量,任意一方更改, 都会影响到另外一方.
小结
这一章我们讲述了指针的基本使用,以及指针在函数中使用带来的变化, 可以简单总结以下几条规则:
1.指针可以控制某些数据结构,灵活地更改它们的值.
2.函数在声明时, 需要考虑使用值类型还是引用类型, 如果需要更改原参那么就选择引用类型或指针.如果不需要就使用值类型.
3.传递数据可以使用指针,它们占据内存更小,更方便.